本文整理自《Unity Shader入门精要》以及LearnOpenGL
综述
渲染流水线的工作任务在于由一个三维场景出发,生成一张二维图像。通常由CPU和GPU共用完成。
《RTR》把整个渲染流程概念化为三个阶段:
应用阶段(CPU)
即准备好场景数据,进行粗粒度的剔除,设置每个模型的渲染状态(材质、纹理、shader等),输出渲染图元。
几何阶段(GPU)
对每个渲染图元进行逐顶点、逐多边形的操作,把顶点坐标变换到屏幕坐标,输出二维顶点坐标以及每个顶点相应的数据。
光栅化阶段(GPU)
对逐顶点数据进行纹理以及颜色插值,再进行逐像素的其他处理,产生屏幕上的像素,渲染出最终的图像。
渲染流水线中CPU与GPU之间的通信
渲染流水线的起点是CPU,所以CPU与GPU之间的通信主要出现在应用阶段:
- 把数据加载到显存当中:硬盘->内存->显存
- 设置渲染状态:设置着色器、光照、材质
- 调用Draw Call:CPU发往GPU的渲染命令,GPU根据渲染状态和传输的数据跑完整个GPU流水线,输出屏幕像素
GPU流水线
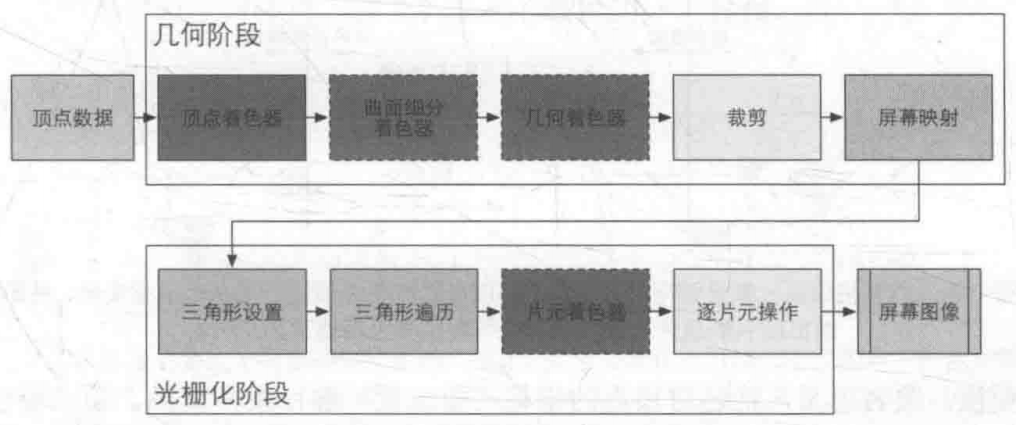
GPU的渲染流水线如上图,GPU从显存中读取顶点数据,进入几何阶段。其中屏幕映射、三角形设置、三角形遍历都是GPU固定实现的(Fixed-function),不可编程或者配置。
几何阶段中包含以下子流水线阶段:
1.顶点着色器(Vertex Shader)
输入顶点数据,对顶点做坐标变换(模拟水或者布料),把顶点坐标从模型空间转换到齐次裁剪空间(视锥体确定的空间,即经过MVP矩阵变换后的空间),做透视除法(xyz除以齐次坐标)后得到归一化后的设备坐标NDC(Normalized Device Coordinates),在OpenGL是(-1,1),再计算顶点颜色;
2.曲面细分着色器(Tessellation Shader)
可选,用于细分图元;
3.几何着色器(Geometry Shader)
可选,用于执行逐图元的着色操作,或用于产生更多的图元;
4.裁剪(Clipping)
将部分在视野内的图元裁剪成两部分,舍弃在NDC立方体外的部分,只将在NDC立方体内的图元传播到下一个环节,这步不可编程,是硬件上的固定操作,但可以进行配置;
5.屏幕映射(Screen Mapping)
把每个图元的x和y坐标转换到屏幕坐标系(和屏幕分辨率有关系)下,不改变z坐标,由此形成窗口坐标系(屏幕坐标系+z坐标);
OpenGL和DirectX的屏幕坐标是反向的
光栅化阶段包含以下子流水线阶段:
1.三角形设置(Triangle Setup)
计算光栅化一个三角网格所需要的信息,由于上一个阶段输出顶点以及额外的信息,并没有包含三角形的边界信息,这一步主要得到三角形边界的表示方式;
2.三角形遍历(Triangle Traversal)
检查每个像素是否被三角网格所覆盖,如果被覆盖,则生成一个片元,这样一个过程就是三角形遍历,也称扫描变换,并且会使用三角网格的顶点信息对所有像素进行插值(深度等),最终输出片元序列,还不是一个真正意义上的像素,而是包含了很多状态的集合(包含屏幕坐标、深度信息、顶点信息、法线以及纹理坐标等),这些状态用于计算像素的最终颜色;
3.片元着色器(Fragment Shader/Pixel Shader)
输入片元信息,输出像素真正的颜色值,此阶段包含纹理采样等渲染技术,但是一般仅能影响单个片元。
4.逐片元操作(Per-Fragment Operations/Output-Merger)
这一阶段决定片元的可见性,主要过程如图:

模板测试(Stencil Test)
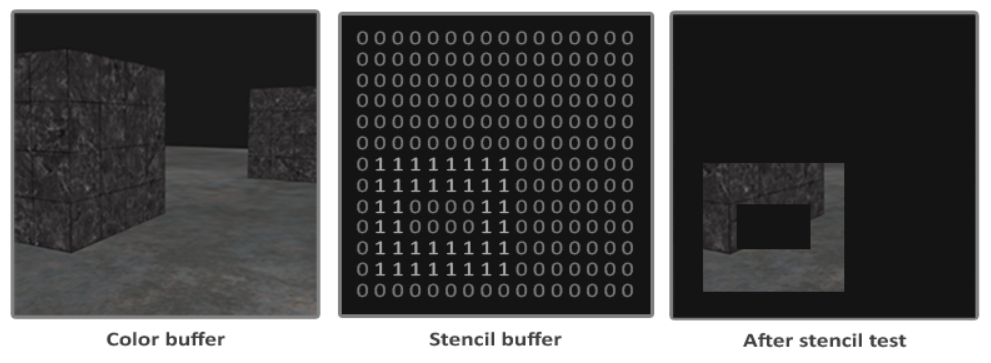
对每个片元,对比它的模板缓冲的值与参考值,并且按照一定规则通过测试,如果通过测试,那么此片元可以进入下一个阶段,通常用于渲染阴影、镜面、轮廓等。
大体步骤如下:
- 启用模板缓冲写入
glStencilMask(0xFF) - 渲染物体,根据物体更新模板缓冲内容(例如物体轮廓的模板缓冲置为1)
glStencilFunc - 禁用模板缓冲写入
glStencilMask(0x00) - 渲染其它气体,这次根据模板缓冲内容丢弃特定片段(例如不绘制原物体轮廓部分)
glStencilFunc
OpenGL相关函数
1 | glStencilMask(0xFF); // 位遮罩(bitmask),每一位写入模板缓冲时都与它进行位加运算,效果为允许 |
1 | glStencilFunc(GLenum func, GLint ref, GLuint mask) // 指定通过模板测试条件,通过测试则 |
1 | glStencilOp(GLenum sfail, GLenum dpfail, GLenum dppass) // 指定测试通过或失败时执行的动作, |
深度测试(Depth Test)
通常用于隐藏面消除的z-buffer算法,通过比较片元的深度来判断片元是否通过深度测试,如果通过测试可以进入下一个测试阶段,最终可绘制出来,此阶段也是可以高度配置的,可用于透明效果的实现。
混合(Blend)
用于半透明物体或者透明物体的实现,如果没有混合操作,就会直接使用片元的颜色覆盖掉颜色缓冲区中的颜色,开了混合后,GPU会取出源色和目标颜色,将两种颜色进行混合。
测试的顺序与性能
通常测试是在片元着色器后进行的,但是这样会浪费计算成本,很多片元着色器计算得到的值并不会显示在最终屏幕上,所以大多数GPU会尽可能在片元着色器之前进行这些测试,以提高性能,但是这样有可能与片元着色器中的操作,例如透明度测试,发生冲突,GPU会判断冲突,如果有冲突,则会禁用提前测试,这也是透明度测试会导致性能下降的原因。
关于Draw Call造成的性能影响
CPU和GPU并行工作
CPU和GPU通过命令缓冲区(Command Buffer)进行协同工作,即一个命令队列,CPU向其中添加命令,GPU从其中读取命令。
Draw Call对性能的影响及优化方法
每次调用Draw Call,CPU需要向GPU发送很多内容,包括数据、状态、命令等,这阶段CPU需要完成很多工作,例如检查渲染状态,待CPU完成这些工作后,GPU才开始渲染,但是GPU的渲染速度通常快于CPU的速度,如果Draw Call太多,CPU会把大量时间花费在提交Draw Call上,造成过载。
那么把大量Draw Call合并成一个Draw Call可以减少Draw Call,这就是批处理(Batching),通常通过在CPU内存中合并静态物体的网格来达到目的。
游戏开发中减少Draw Call的开销,需要注意:
- 避免使用大量很小的网格,同时尽量合并它们;
- 避免使用过多的材质;